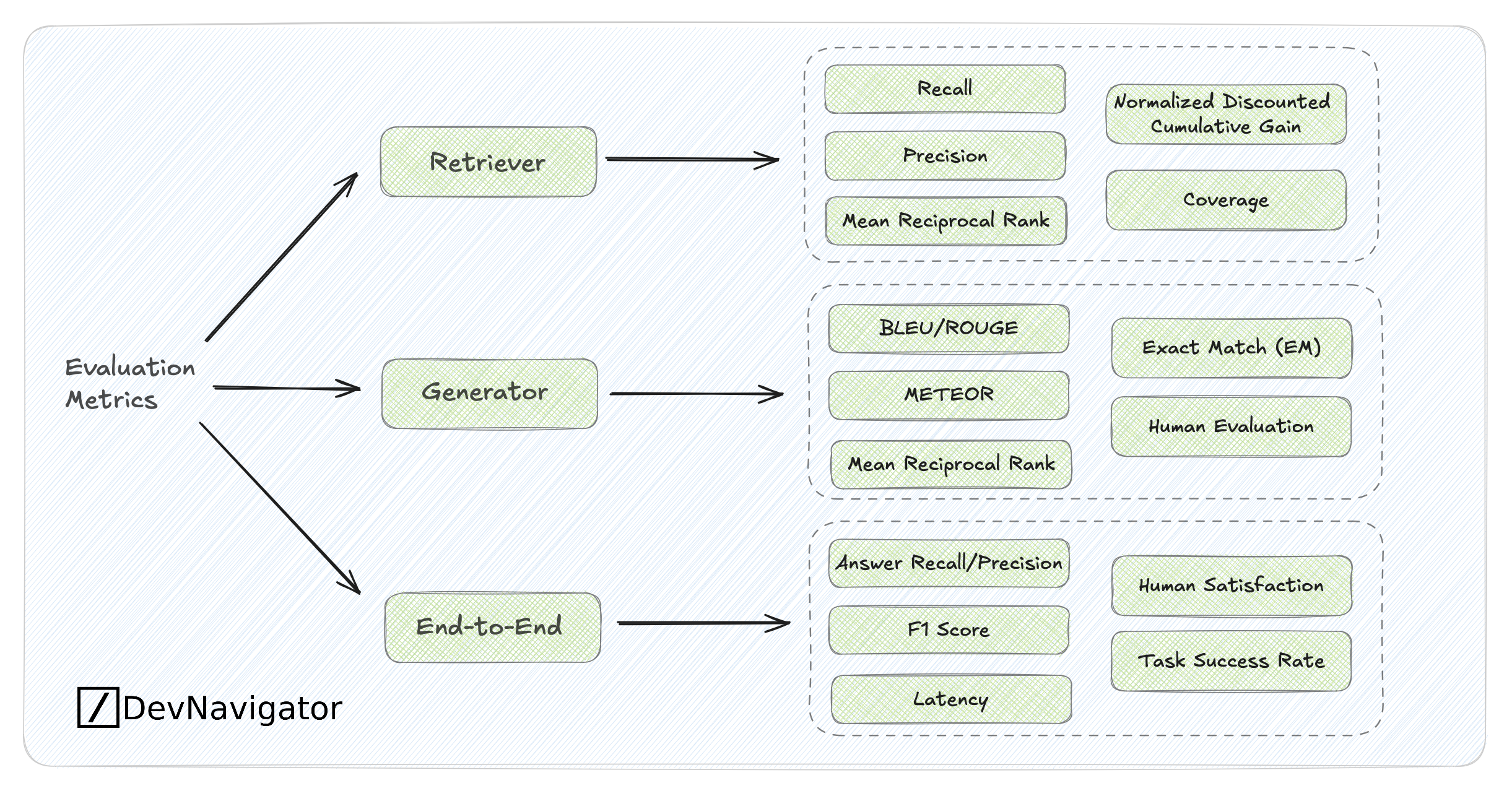
Evaluating retrieval-augmented or generative AI systems requires different layers of measurement, retrievers are judged by how effectively they surface relevant information, generators by the quality and fidelity of their responses, and end-to-end systems by real-world performance and user satisfaction. The diagram organizes these metrics, linking retrieval precision and ranking scores with generation quality measures like BLEU, ROUGE, and human evaluation, culminating in holistic outcomes such as accuracy, latency, and task success rate.