
The FAIR Data Framework has evolved from an academic best practice into a practical operating model for organizations modernizing their data and AI capabilities. As enterprises face exploding data volumes, cross-functional analytics demands, and accelerating AI adoption, data must be more than stored. It must be easy to find, securely accessed, seamlessly integrated, and confidently reused. The FAIR Data Framework provides a clear, actionable structure to achieve exactly that. By embedding FAIR principles into data platforms, governance models, and workflows, organizations transform fragmented information into a scalable, trusted asset that supports speed, quality, and long-term innovation.
Table of Contents
Executive Takeaways
- FAIR Data Framework accelerates insight delivery by ensuring datasets are easy to locate, understand, and trust across teams and tools.
- FAIR Data Framework strengthens governance without slowing teams down, balancing access, security, and compliance through standardized methods.
- FAIR Data Framework enables AI at scale, making data reusable, interoperable, and fit for advanced analytics and automation.
Expanded Insights
Why the FAIR Data Framework Matters Now
The FAIR Data Framework has gained momentum because it solves a problem that has only intensified with AI. Organizations are no longer limited by data scarcity. They are constrained by data fragmentation, poor documentation, inconsistent formats, and unclear ownership. When teams cannot find the right data or trust what they find, analytics slows, AI models degrade, and decision-making becomes reactive.
The FAIR Data Framework addresses this challenge directly by shifting focus from data storage to data usability. It provides a shared language and structure that aligns data producers, platform teams, analysts, and AI practitioners around a single goal: making data usable by design.
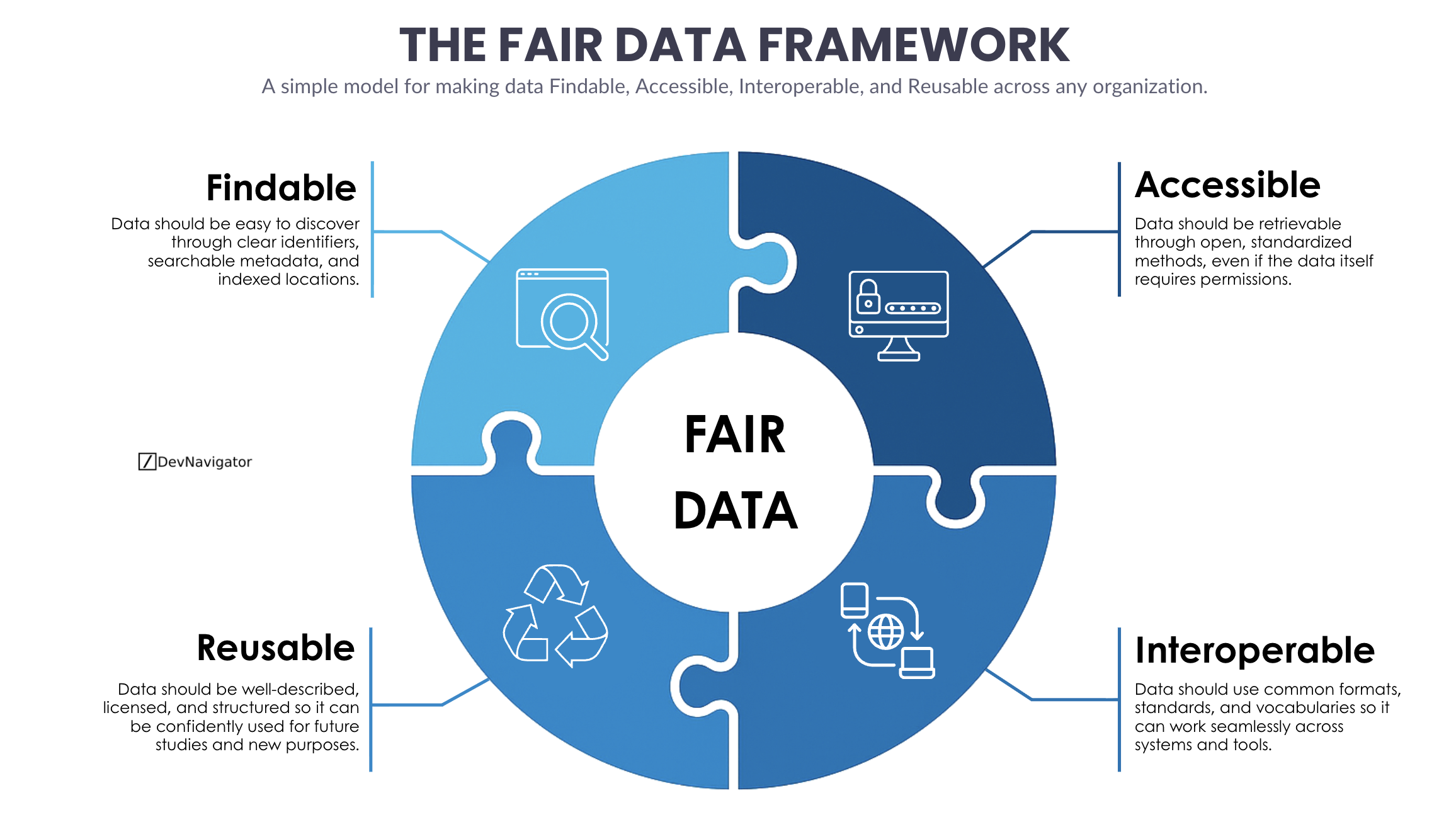
Findable Data Enables Speed and Confidence
Findability is the entry point of the FAIR Data Framework. Data that cannot be discovered might as well not exist. In practice, this means assigning clear identifiers, maintaining searchable metadata, and indexing datasets in ways that match how teams actually work.
Strong findability reduces time wasted searching for data, recreating datasets, or validating unknown sources. It also improves confidence, since teams understand what a dataset represents before using it. In AI workflows, this becomes critical. Model performance and explainability depend on knowing where training data came from, how it was generated, and what it represents.
Accessible Data Balances Security and Usability
Accessibility is often misunderstood as unrestricted access. The FAIR Data Framework is more nuanced. Data should be retrievable through standardized, well-defined mechanisms, even if access itself is controlled.
This distinction matters in regulated environments. A dataset can be FAIR and still protected. What matters is that authorized users and systems can reliably access it using consistent interfaces. APIs, standardized query layers, and controlled authentication methods all support this goal.
By separating access methods from access permissions, the FAIR Data Framework allows organizations to scale analytics and AI while maintaining governance, auditability, and compliance.
Interoperability Breaks Down Silos
Interoperability is where the FAIR Data Framework starts delivering exponential value. Data rarely creates value in isolation. It becomes powerful when it can move across systems, tools, and domains without costly transformation.
Common formats, shared vocabularies, and aligned data models_toggle friction between platforms. This is especially important for AI pipelines, where data often flows from source systems to feature stores, training environments, deployment platforms, and monitoring tools. Interoperability ensures that data remains usable at every step, not just at ingestion.
Reusability Unlocks Long-Term Scale
Reusability completes the FAIR Data Framework by extending the value of data beyond its original purpose. Well-described, licensed, and structured datasets can support future analyses, new AI models, and unforeseen use cases without constant rework.
This is where organizations see compounding returns. Instead of treating data as a one-time asset, the FAIR Data Framework enables reuse across projects, teams, and time. It reduces duplication, improves consistency, and strengthens trust in analytics outcomes.
FAIR as a Foundation for AI Maturity
The FAIR Data Framework is not an academic ideal. It is a practical prerequisite for reliable AI. Models trained on poorly documented, inaccessible, or inconsistent data amplify risk and uncertainty. FAIR data, by contrast, supports explainability, traceability, and responsible scaling.
Organizations that adopt the FAIR Data Framework position themselves to move faster with less risk. They enable analytics teams to focus on insight, AI teams to focus on performance, and leaders to focus on outcomes. FAIR transforms data from a bottleneck into a strategic accelerator for digital excellence.