
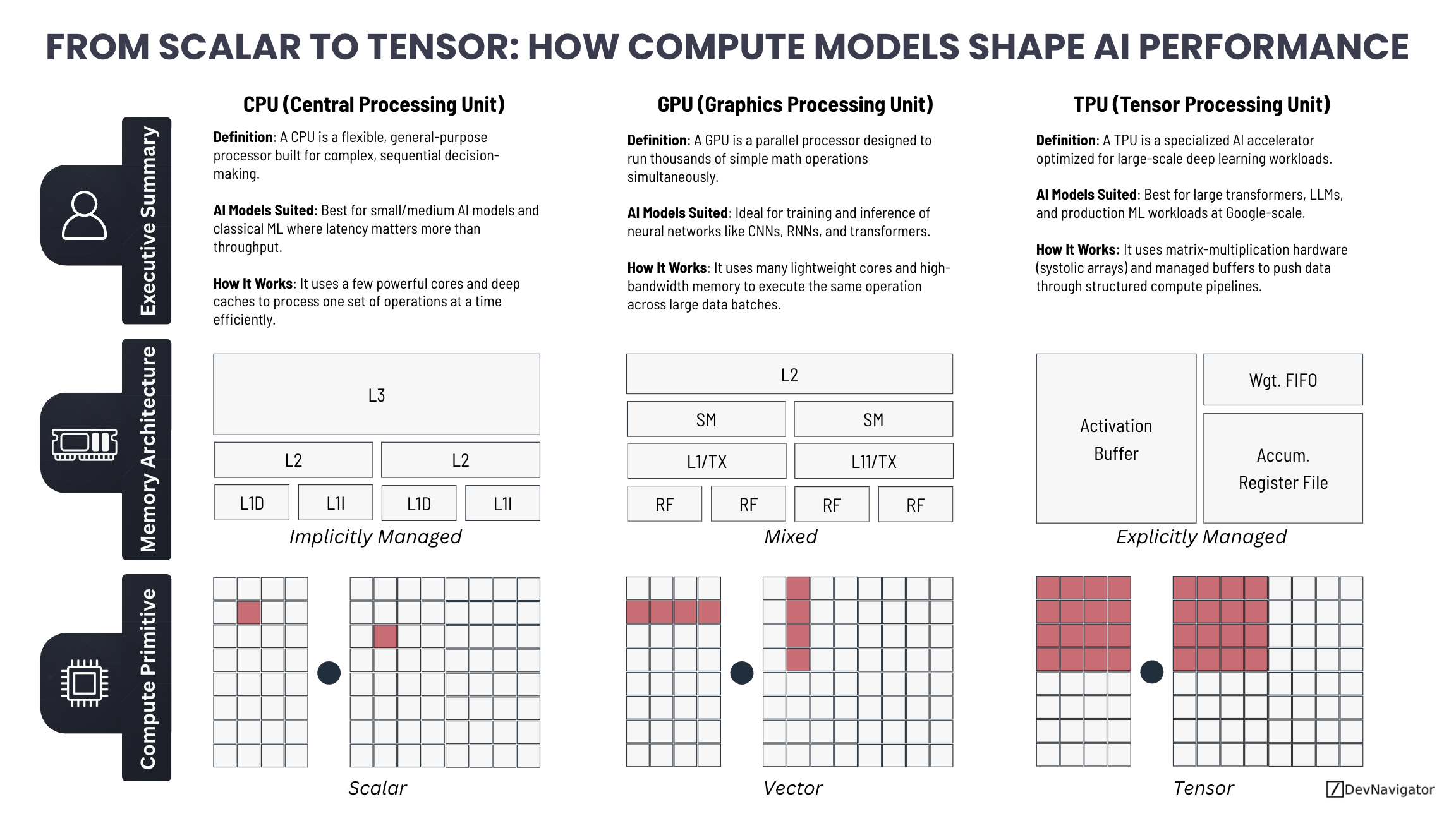
Artificial intelligence performance is no longer just about better models. It is increasingly about how those models are executed. Understanding how compute architectures align with different AI workloads has become a strategic decision for teams building, scaling, and operating modern AI systems. The distinction between CPUs, GPUs, and TPUs is not academic, it directly impacts speed, cost, reliability, and scalability. This article explains how compute models shape AI performance, and why choosing the right one matters.
As AI systems grow more complex, performance depends less on raw model capability and more on how efficiently computations are executed. How compute models shape AI performance comes down to matching workload structure to processor architecture. Scalar, vector, and tensor computation are not interchangeable abstractions, they represent fundamentally different execution strategies that determine how well AI workloads scale in practice.
Executive Takeaways
- CPU, GPU, and TPU architectures optimize for different compute primitives (scalar, vector, tensor), directly influencing AI performance efficiency.
- GPUs and TPUs dramatically accelerate neural networks, while CPUs remain critical for orchestration, control logic, and end-to-end system integration.
- Selecting the right compute model is about alignment, not speed, ensuring performance, cost efficiency, and scalability at scale.
Expanded Insights
Scalar Compute and the Role of CPUs
CPUs are designed for flexibility. They excel at scalar computation, processing one instruction stream at a time with sophisticated control logic, branching, and caching. This makes CPUs ideal for tasks where execution paths vary frequently or depend on conditional logic. Traditional machine learning algorithms, feature engineering, data preprocessing, and system orchestration all benefit from this design.
In real-world AI systems, CPUs rarely disappear. They schedule workloads, manage memory, handle I/O, and coordinate interactions between accelerators. Even in GPU- or TPU-heavy environments, CPUs remain the backbone that keeps the system coherent. When AI workloads involve decision trees, rule-based logic, or dynamic control flow, CPUs often outperform more specialized hardware.
Vector Compute and GPU Acceleration
GPUs introduced a shift from scalar to vector-based computation. Instead of executing one operation at a time, GPUs apply the same operation across large blocks of data simultaneously. This architecture aligns naturally with neural networks, where the same mathematical operations are repeated across massive tensors.
Training convolutional networks, transformers, and other deep learning models would be impractical at scale without GPUs. Their ability to process thousands of operations in parallel makes them the default choice for both training and inference in many enterprise and research settings. However, GPUs rely on a mixed memory model, combining hardware-managed caches with programmer-controlled memory, which requires careful optimization to achieve peak performance.
Tensor Compute and TPUs
TPUs represent the most specialized end of the compute spectrum. They are purpose-built for tensor operations, particularly matrix multiplication, which dominates modern deep learning workloads. By removing general-purpose features and focusing on structured data flow through systolic arrays, TPUs achieve exceptional efficiency at scale.
This specialization makes TPUs highly effective for large transformer models, LLM training, and high-throughput inference pipelines. The tradeoff is flexibility. TPUs perform best when workloads conform closely to their execution model. For organizations operating large, standardized AI workloads in cloud environments, TPUs can deliver significant cost and performance advantages.
Why Architecture Alignment Matters
Understanding how compute models shape AI performance is ultimately about alignment. CPUs handle control and variability. GPUs handle parallel numeric intensity. TPUs handle structured tensor math at scale. No single architecture replaces the others.
Modern AI platforms increasingly rely on orchestration across all three. A typical workflow may preprocess data on CPUs, train models on GPUs, and deploy large-scale inference on TPUs or other accelerators. Performance bottlenecks often arise not from model design, but from mismatches between workload structure and compute architecture.
The Future of AI Compute
The future of AI compute will be heterogeneous. As models grow larger and workflows more complex, success will depend on the ability to route tasks intelligently across CPUs, GPUs, and TPUs. Organizations that treat compute as a strategic design choice, rather than an afterthought, will be better positioned to scale AI efficiently and sustainably.
AI performance is no longer just about smarter models. It is about smarter compute decisions.