
Large Language Models are often described as intelligent systems that are foundational to much of the work today surrounding Agentic AI, yet the way they actually operate remains opaque to many leaders and practitioners. This article provides a clear, step by step explanation of how transformer based language models process input, build contextual meaning, and generate responses. By separating what happens during training from what happens during inference, the goal is to demystify LLMs without relying on code or mathematical detail. Understanding this workflow helps organizations set realistic expectations, communicate AI capabilities more effectively, and design better applications that align with how these models truly work.
Table of Contents
Executive Takeaways
- Large Language Models rely on a structured sequence of steps that transform raw text into contextual representations and probabilistic predictions.
- The same core processing pipeline is used during training and inference, but only training updates the model’s internal parameters.
- In context learning influences how a model behaves during a session, not what it fundamentally knows.
Expanded Insights
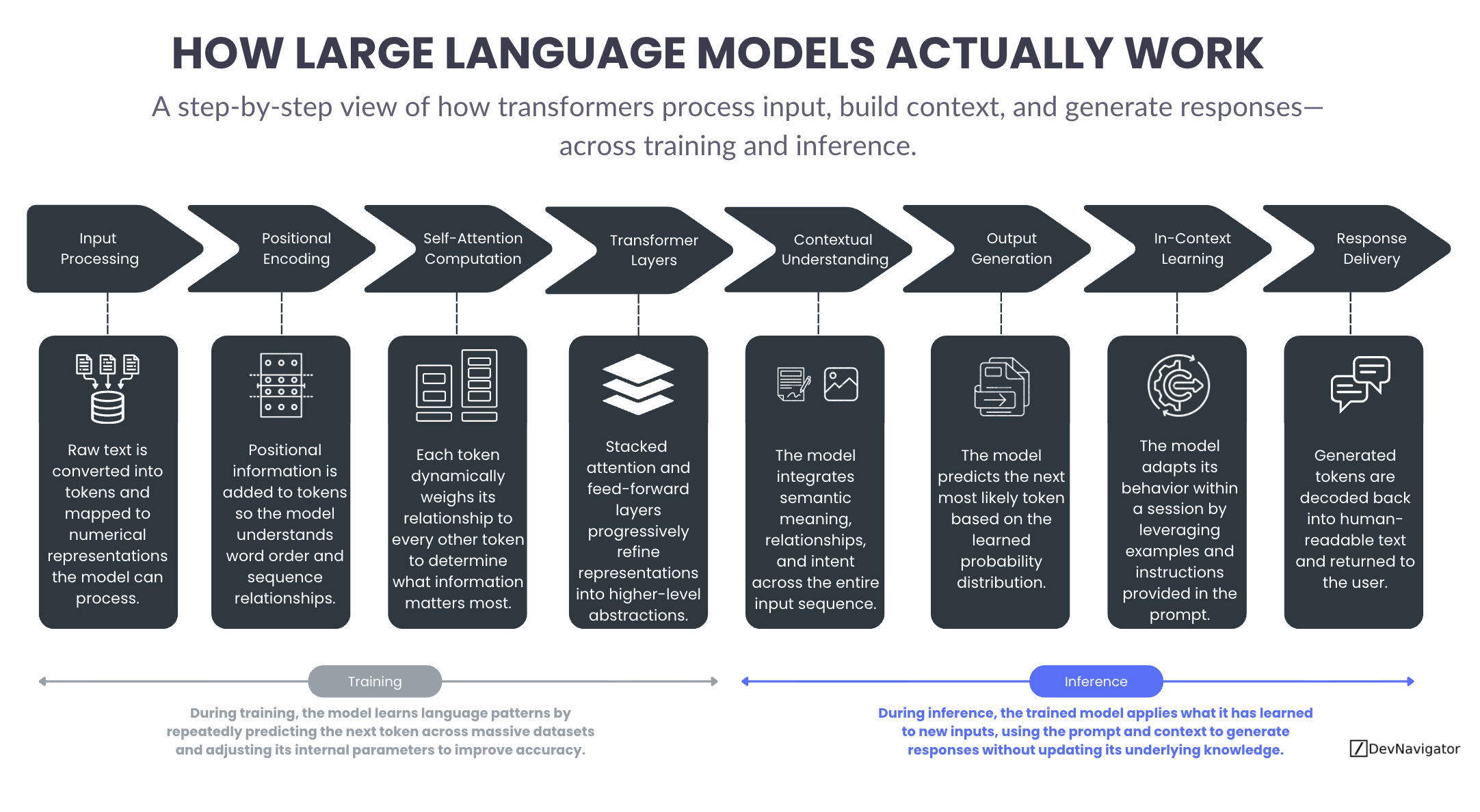
From Text to Tokens: Preparing Language for the Model
Every interaction with a Large Language Model begins by transforming raw text into a format the model can process. During input processing, text is broken into tokens and mapped to numerical representations. These tokens are not words in the human sense, but discrete units that allow the model to scale across languages, domains, and writing styles. This step creates the foundation for everything that follows, enabling language to be handled mathematically rather than symbolically.
To preserve meaning, positional encoding is added next. Neural networks do not inherently understand sequence or order, so positional information provides structure. This allows the model to distinguish between sentences with the same words arranged differently and to understand relationships such as cause and effect, sequence, and emphasis. Without positional encoding, language would lose much of its semantic integrity.
Self Attention: How Context Is Built
The defining capability of transformer models emerges through self attention computation. Instead of processing text one token at a time, the model evaluates how each token relates to every other token in the input. This allows it to determine which pieces of information matter most in context. A word early in a sentence can influence the interpretation of a word much later, even across long passages of text.
Self attention enables models to capture dependencies that traditional sequence based models struggled with. It is the reason LLMs can resolve references, connect ideas across paragraphs, and maintain coherence in extended responses. This process does not involve understanding in a human sense, but it does allow the model to weight information dynamically based on context.
Transformer Layers: Refining Meaning Through Depth
Self attention operates within transformer layers that are stacked repeatedly. Each layer applies attention and feed forward transformations that refine the model’s internal representations. Early layers tend to capture surface level patterns, while deeper layers encode increasingly abstract and semantic information.
As tokens pass through these layers, the model constructs richer representations that reflect meaning, relationships, and intent. This layered refinement is what allows LLMs to perform tasks such as summarization, reasoning over text, and adapting tone. The depth of these layers plays a major role in model capability, though it also increases computational cost.
Contextual Representation: Meaning as an Emergent Property
What is often labeled as contextual understanding is not a separate component, but an emergent result of attention and layered processing. By integrating information across the entire input sequence, the model forms contextualized representations that allow it to respond coherently rather than reacting to isolated tokens.
This is why modern LLMs can follow instructions, answer follow up questions, and maintain consistency across multi turn interactions. The model is not storing memory or forming beliefs, but it is continuously recalculating context as new tokens are introduced.
Output Generation: Predicting the Next Token
Once contextual representations are formed, output generation begins. The model predicts the next most likely token based on learned probability distributions. This prediction is influenced by everything that came before, including the prompt, prior outputs, and the broader context.
Responses are generated one token at a time, with each new token becoming part of the context for the next prediction. While this process is probabilistic, the distributions reflect patterns learned during training across massive datasets. What appears as fluent language is the result of many small, sequential probability decisions.
In Context Learning: Adapting Without Learning
In context learning often creates the impression that a model is learning during a conversation. In reality, the model adapts its behavior within a session by leveraging examples, instructions, and formatting provided in the prompt. This influences how the model responds, but it does not change its internal parameters or long term knowledge.
This distinction is critical for setting expectations. The model does not remember past conversations or accumulate new knowledge during deployment. It responds based on context provided in the moment. Additional context is often introduced into large language models through retrievers such as RAG, HyDE, or even GraphRAG.
Training vs Inference: Building vs Applying Capability
The same processing pipeline underpins both training and inference. During training, the model repeatedly runs this forward process across large datasets, compares its predictions to known outcomes, and adjusts its internal parameters to improve accuracy. This is where capability is created.
During inference, the trained model applies what it has learned to new inputs. The forward process remains the same, but the internal parameters are fixed. Training builds the model. Inference uses it.
Understanding this distinction helps organizations communicate AI capabilities, especially within the context of large language models, more accurately and design systems that align with how Large Language Models actually work, rather than how they are often perceived.