
As reinforcement learning increasingly shifts from isolated research experiments to agentic systems embedded in real workflows, infrastructure has become the limiting factor. Training modern AI agents often requires distributed GPUs, complex orchestration, and tight coupling between environment design and execution. OpenTinker addresses this challenge by delivering agentic reinforcement learning as a service. Its cloud-native architecture cleanly separates environment design, training orchestration, and execution, allowing teams to scale learning without owning or managing GPU infrastructure. This article breaks down what OpenTinker is, how it works, and why this design matters as organizations move toward production-grade AI agents.
Table of Contents
Executive Takeaways
- OpenTinker transforms agentic reinforcement learning into a service by decoupling environments, training, and execution.
- A centralized scheduler and distributed GPU workers enable scalable training and inference without local infrastructure.
- The architecture accelerates iteration, improves observability, and makes agentic RL more operationally reliable.
Expanded Insights
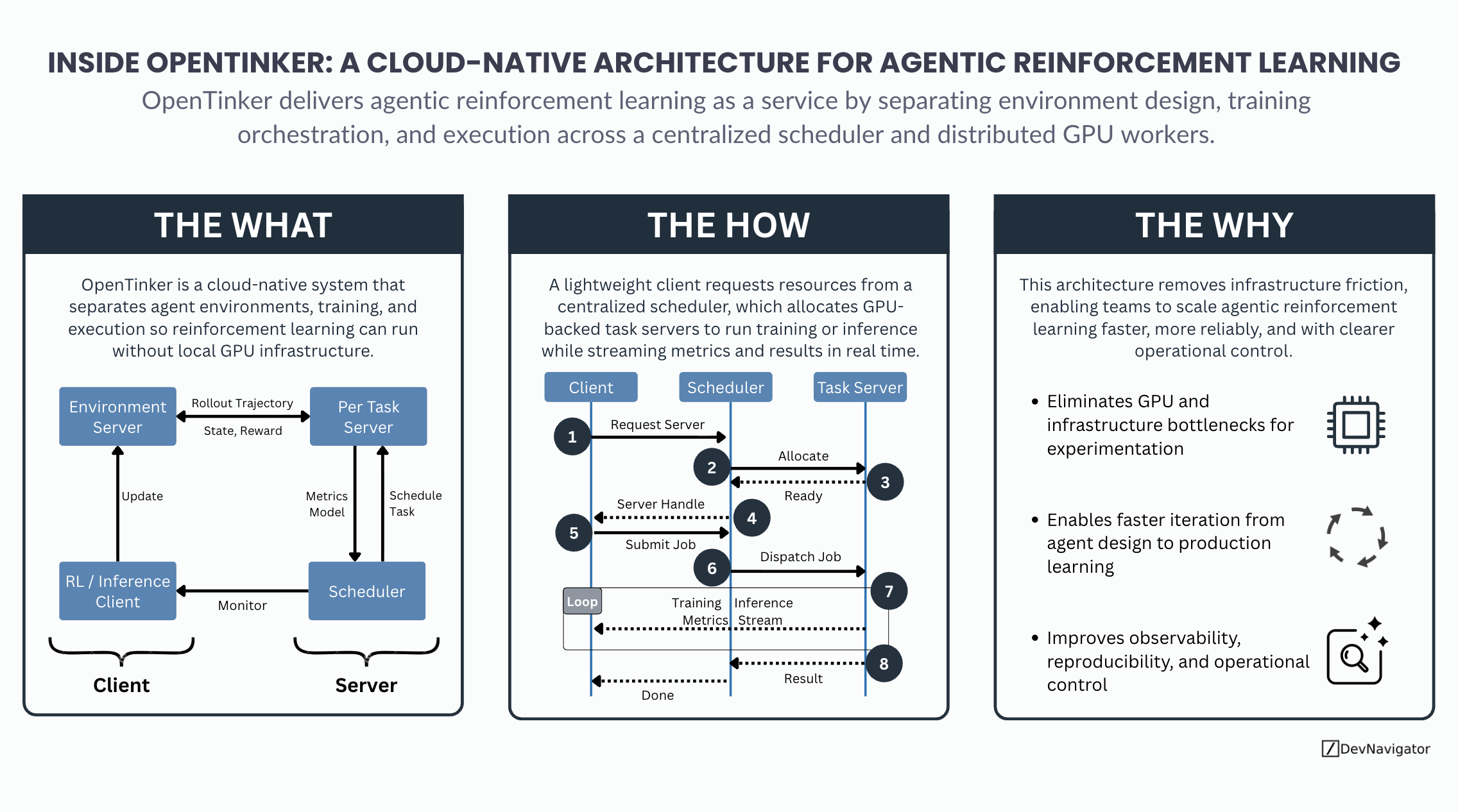
From Monolithic Pipelines to Decoupled Learning Systems
Traditional reinforcement learning pipelines tend to bundle everything together. Environment logic, training loops, and execution often live in the same runtime, tightly coupled to specific hardware. This approach works for small experiments but breaks down quickly as tasks become multi-turn, data sources diversify, or GPU demands increase. OpenTinker takes a different path. It treats agent environments, orchestration, and execution as distinct concerns. By separating these layers, teams can design and evolve agent behaviors independently from the infrastructure used to train them.
What OpenTinker Is Solving
At its core, OpenTinker is a cloud-native system for running agentic reinforcement learning without requiring local GPUs. Environments define how agents interact with tasks, whether those tasks are single-turn reasoning problems or multi-turn games and tool-calling workflows. Training and inference, however, are handled remotely. This separation allows developers to focus on agent design while the platform manages scheduling, execution, and resource allocation behind the scenes.
How the Architecture Works
The operational flow is intentionally simple. A lightweight client submits a request to a centralized scheduler, describing the training or inference job and its requirements. The scheduler allocates one or more GPU-backed task servers from a worker pool and launches the job. Once execution begins, metrics such as rewards or loss values stream back to the client in real time, providing continuous visibility into progress. When training completes, results and model artifacts are returned in a controlled, reproducible way.
This design turns what is usually a fragile, bespoke setup into a repeatable service. The client remains thin, the scheduler handles coordination, and the task servers focus solely on execution. Each component has a clear role, which reduces system complexity and operational risk.
Why This Matters for Agentic AI
Agentic reinforcement learning introduces new demands compared to traditional model training. Multi-turn interactions, tool use, and environment feedback loops require flexible execution models and careful state management. While other implementations often use Reinforcement Learning for GraphRAG, OpenTinker’s architecture supports these needs by design. Because environments are abstracted and execution is remote, the same agent logic can be trained, evaluated, and deployed across different scales without modification.
This approach also improves iteration speed. Teams can experiment with new environments or reward structures without provisioning new hardware or rewriting orchestration logic. As a result, learning cycles shorten, and agents can move from prototype to production more smoothly.
Operational Benefits Beyond Scale
Beyond raw scalability, OpenTinker brings important operational benefits. Centralized scheduling improves observability by making job status, metrics, and outputs first-class concepts. Reproducibility improves because training runs are managed consistently, with clear inputs and outputs. Perhaps most importantly, infrastructure friction is reduced. GPU access, resource contention, and execution failures become platform concerns rather than developer distractions.
A Step Toward Production-Ready Agent Learning
OpenTinker reflects a broader shift in how reinforcement learning is being applied. As organizations adopt agentic systems in real products, learning infrastructure must evolve from research tooling into dependable platforms. By delivering reinforcement learning as a service, OpenTinker helps bridge that gap. It enables teams to treat agent learning as an operational capability rather than a specialized experiment, laying the groundwork for scalable, reliable AI agents in production environments.