
Prompt caching is one of the most important cost and performance optimizations quietly shaping modern LLM applications. As teams scale agents, RAG pipelines, and long-context workflows, the same large prompt prefixes are often sent to models again and again. Prompt caching exploits this repetition, allowing providers to reuse previously computed context instead of recomputing it from scratch on every request. The result is faster responses and dramatically lower input token costs.
Table of Contents
Executive Takeaways
- Prompt caching works by reusing the shared prefix of a prompt, not by reusing the model’s final answer.
- Providers cache internal attention states for repeated context, eliminating redundant computation.
- The biggest gains appear in long, structured prompts used across many requests, such as agents and RAG systems.
Expanded Insights
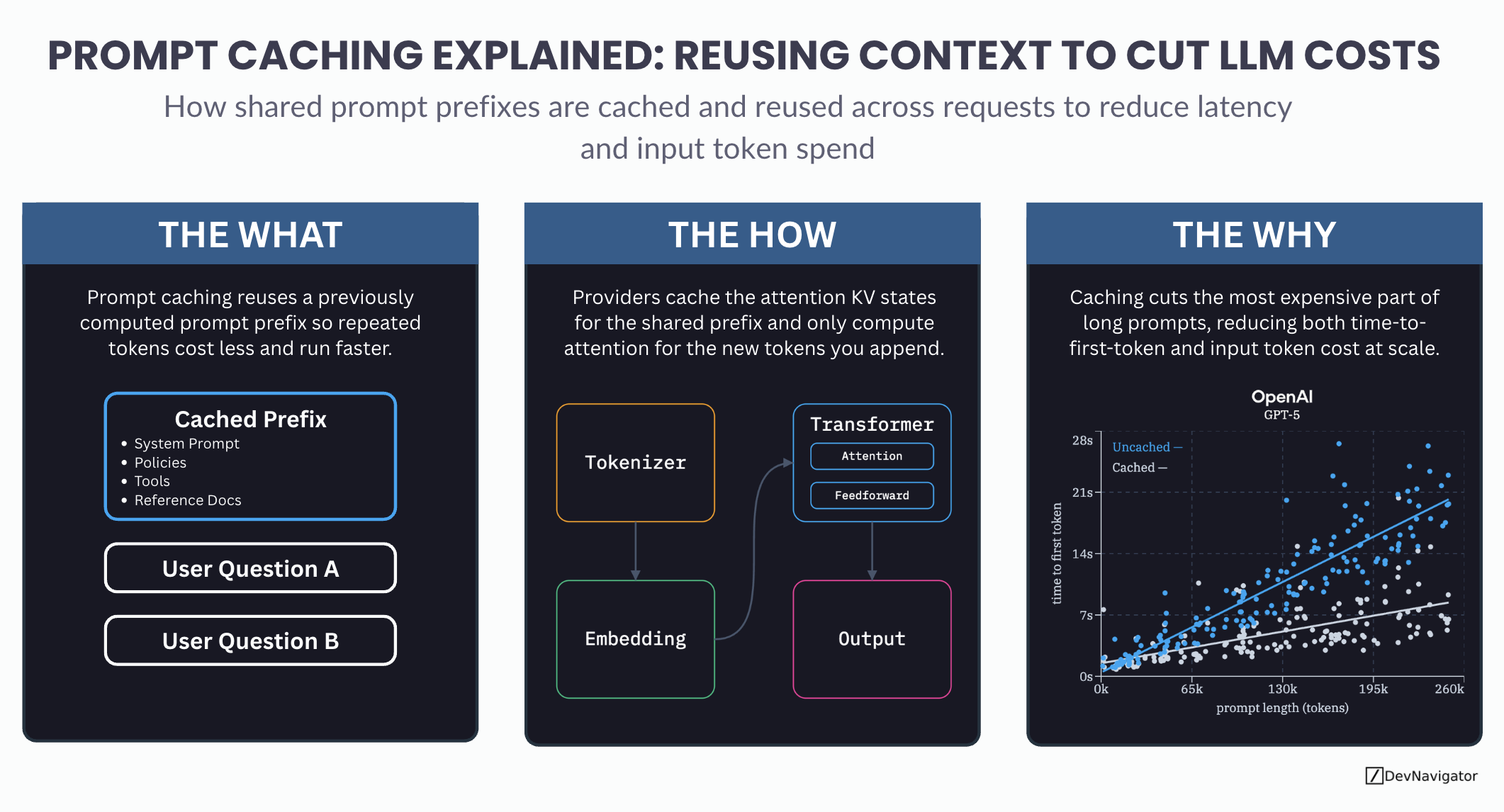
The What: What Prompt Caching Actually Is
At a high level, prompt caching means that an LLM provider remembers the expensive work associated with a previously processed prompt prefix. When a new request begins with the same prefix, the model can skip recomputing that portion and focus only on the new tokens that follow.
This cached prefix typically includes elements such as system instructions, safety policies, tool definitions, and reference documents. These components rarely change across requests, yet they often account for most of the prompt length. By reusing them, repeated tokens cost less and execute faster.
Importantly, prompt caching does not mean the model is replaying a stored response. Each request still generates a fresh output. Only the internal representations of the shared context are reused.
The How: What Is Actually Being Cached
Under the hood, modern transformer models rely on attention mechanisms to process context. During inference, each token produces internal Key and Value states that describe how it should attend to other tokens in the prompt.
Prompt caching stores these attention KV states for the shared prefix. When a new request arrives with the same prefix, the model loads those cached states instead of recomputing them. Attention is then computed only for the newly appended tokens.
This optimization drastically reduces the amount of matrix multiplication required during inference. Since attention over long prompts is one of the most expensive operations in a transformer, caching delivers outsized performance and cost improvements without changing model quality.
The Why: Why Prompt Caching Matters at Scale
As prompt length increases, inference cost and time-to-first-token grow rapidly. This is especially true in applications that rely on long, structured context, such as AI agents, multi-step workflows, or retrieval-augmented generation systems.
Prompt caching attacks the most expensive part of these requests. By eliminating repeated attention computation for unchanged context, providers reduce both latency and input token cost. This effect compounds at scale, where the same prompt template may be reused thousands or millions of times.
For teams building production AI systems, prompt caching is no longer an optional optimization. It is a foundational technique for controlling costs, improving responsiveness, and enabling complex workflows without runaway token spend.
Where Prompt Caching Shines Most
Prompt caching delivers the most value in scenarios where prompt prefixes are long and stable. Common examples include agent frameworks, chat systems with large system prompts, RAG pipelines with fixed instructions, and evaluation or batch inference jobs.
The key requirement is consistency. Small changes in wording or ordering can break cache reuse. Designing prompts with a clean, stable prefix and a clearly separated dynamic section is essential to fully benefit from caching.
Closing Thoughts
Prompt caching is a reminder that LLM performance is not just about model choice. Architecture, prompt design, and inference mechanics matter just as much. Teams that understand and exploit these details gain a meaningful advantage in both cost efficiency and user experience.
As LLM usage continues to scale, prompt caching will increasingly define the difference between prototypes that work and systems that last.