
As organizations scale, data complexity grows faster than human capacity to manage it. OpenAI’s internal experience shows that traditional dashboards, SQL-heavy workflows, and centralized analytics teams are no longer sufficient. The Enterprise Data Agent represents a shift in how organizations interact with data, moving from static reporting to dynamic, conversational analysis grounded in institutional knowledge. This article breaks down how OpenAI designed its Enterprise Data Agent, why it works, and what leaders can learn from its architecture, context strategy, and governance model. The goal is not automation for its own sake, but faster, more reliable decisions without sacrificing trust, security, or accuracy.
Table of Contents
Executive Takeaways
- Enterprise Data Agent design is about context, not just models. Accuracy improves when schema metadata, code logic, and institutional knowledge are treated as first-class inputs.
- Self-correcting workflows outperform rigid analytics pipelines. Allowing an Enterprise Data Agent to inspect, retry, and adapt reduces silent analytical errors.
- Trust scales through permissions, memory, and evaluation. The strongest Enterprise Data Agent systems enforce access control while continuously validating output quality.
Expanded Insights
Why the Enterprise Data Agent Exists
The core problem OpenAI faced was not a lack of data or analytical tools. It was friction. With thousands of users, tens of thousands of datasets, and hundreds of petabytes of data, even finding the right table became a bottleneck. Similar tables differed in subtle but critical ways, leading to confusion, rework, and fragile analyses.
The Enterprise Data Agent was built to remove this friction. Instead of forcing employees to reason through schemas, joins, and historical tribal knowledge, the agent acts as an intelligent interface layer. It allows users to move from question to insight using natural language while still producing auditable, verifiable results.
Architecture That Mirrors How Teams Actually Work
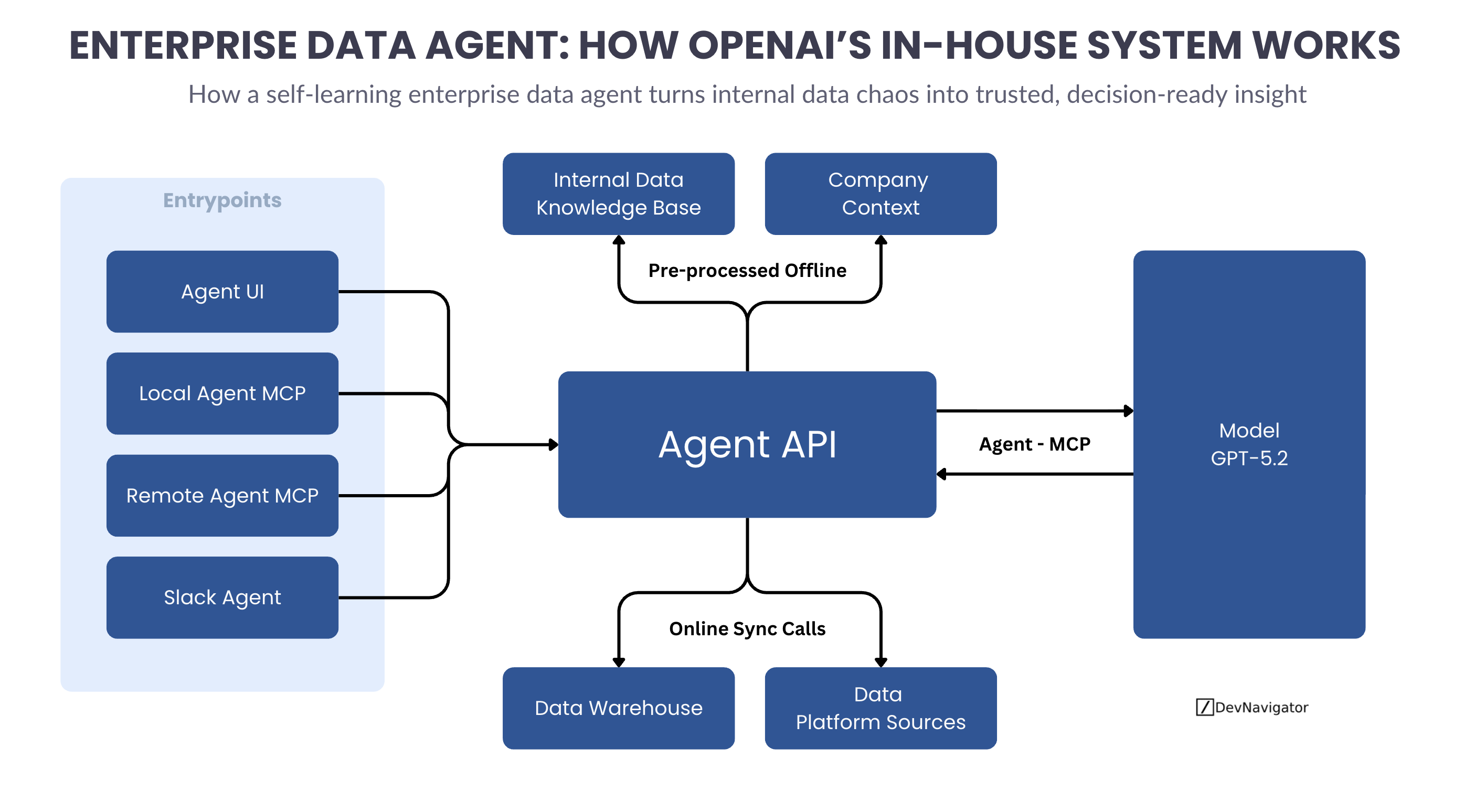
The Enterprise Data Agent is designed to meet users where they already operate. It integrates into Slack, web interfaces, IDEs, and command-line tools through MCP. Behind the scenes, requests flow through a centralized Agent API that coordinates data access, context retrieval, and model reasoning.
This separation matters. The agent does not bypass existing systems. It orchestrates them. Offline preprocessing builds deep contextual knowledge from metadata, historical queries, annotations, and code. Online execution pulls only what is necessary at runtime, keeping latency predictable and costs controlled.
Context Is the Real Differentiator
What separates a basic analytics chatbot from a true Enterprise Data Agent is layered context. OpenAI’s system grounds reasoning across six levels, including table usage patterns, human annotations, code-level enrichment, institutional documentation, learned memory, and live runtime inspection.
This approach prevents common failures such as miscounted metrics or incorrect joins. For example, understanding how a table is produced in Spark or Python often reveals exclusions or assumptions that never appear in SQL alone. The Enterprise Data Agent uses this information automatically, reducing reliance on individual expertise.
Self-Correction Beats One-Shot Answers
A defining capability of the Enterprise Data Agent is its ability to evaluate its own progress. If a query returns zero rows or produces unexpected results, the agent investigates, adjusts filters or joins, and retries. This closed-loop behavior mirrors how experienced analysts work but executes at machine speed.
Instead of pushing iteration back to the user, the Enterprise Data Agent absorbs that burden. The result is faster convergence on correct answers and fewer silent analytical errors that erode trust.
Memory Turns Experience into Capability
The Enterprise Data Agent improves over time by storing non-obvious learnings. When a correction is identified or a nuance is discovered, the agent can save it as memory for future use. These memories can be scoped globally or personally, allowing best practices to propagate without overwriting individual workflows.
This capability transforms repeated questions from recurring costs into compounding assets. Over time, the Enterprise Data Agent starts from a more accurate baseline rather than relearning the same lessons.
Evaluation and Security Are Non-Negotiable
OpenAI treats evaluation as continuous testing, not an afterthought. The Enterprise Data Agent is validated using curated question and answer pairs with known correct outputs. Generated queries are compared against expected results using both SQL and data-level checks.
Security is enforced through strict pass-through permissions. The agent can only access data the user is already authorized to see, reinforcing trust and compliance while expanding analytical reach.