
-
Multi-Graph Agentic Memory: Why This Powerful Architecture Changes How AI Agents Reason

Multi-Graph Agentic Memory represents a fundamental shift in how AI agents store, retrieve, and reason over long-term information. Rather than…
-
AI Agents: The 3×3 Strategic Framework for Effectively Balancing Value, and Feasibility

AI Agents are moving quickly from experimentation to real operational impact, yet many organizations struggle to decide which agent types…
-
Agentic Drug Discovery: 4 Powerful Ways PharmAgents Reframes the Real Pharma Workflow
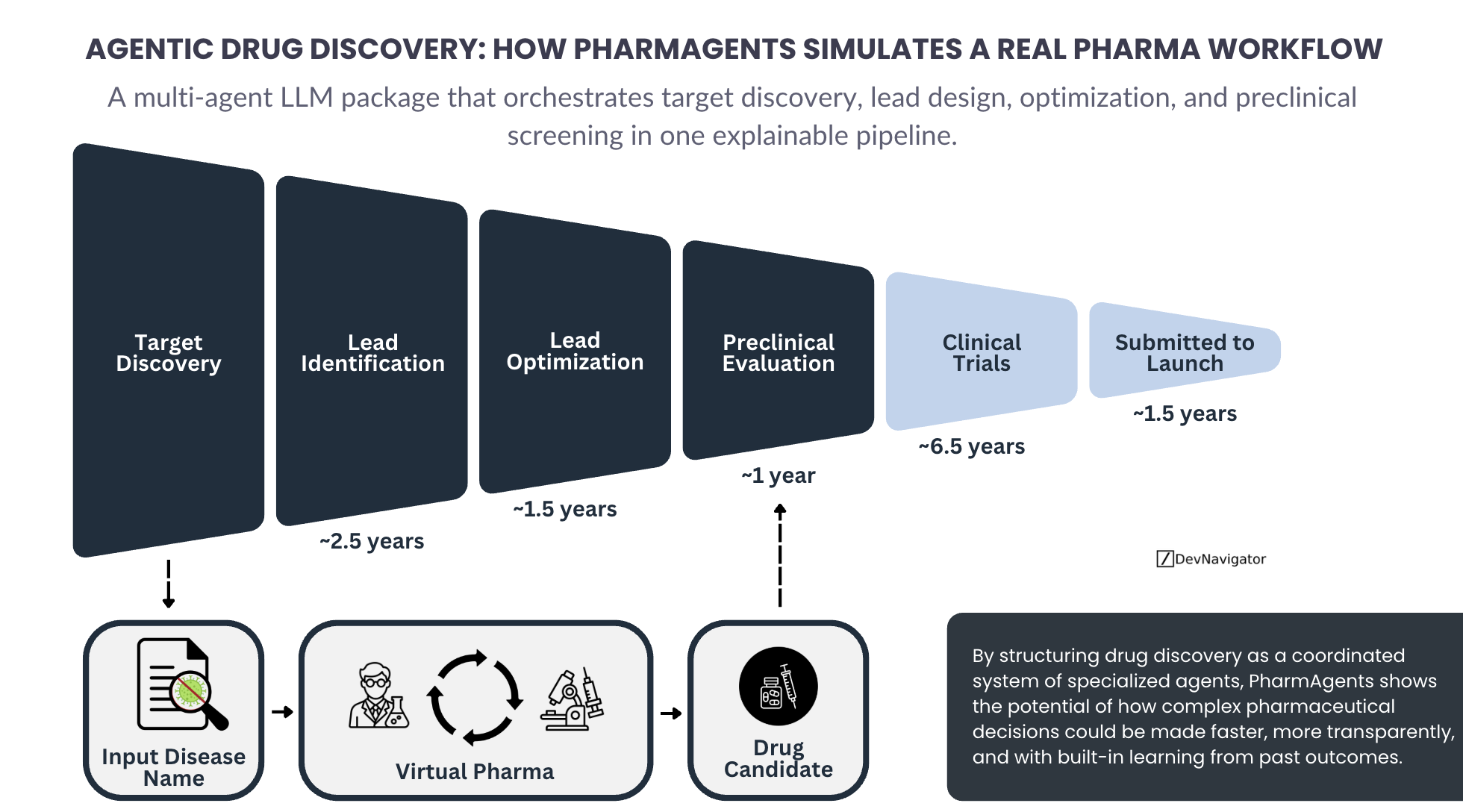
Agentic Drug Discovery is emerging as a practical framework for structuring complex pharmaceutical work using coordinated AI agents rather than…
-
Dynamic LLM Routing: The 6 Takeaways on Improving Output Quality
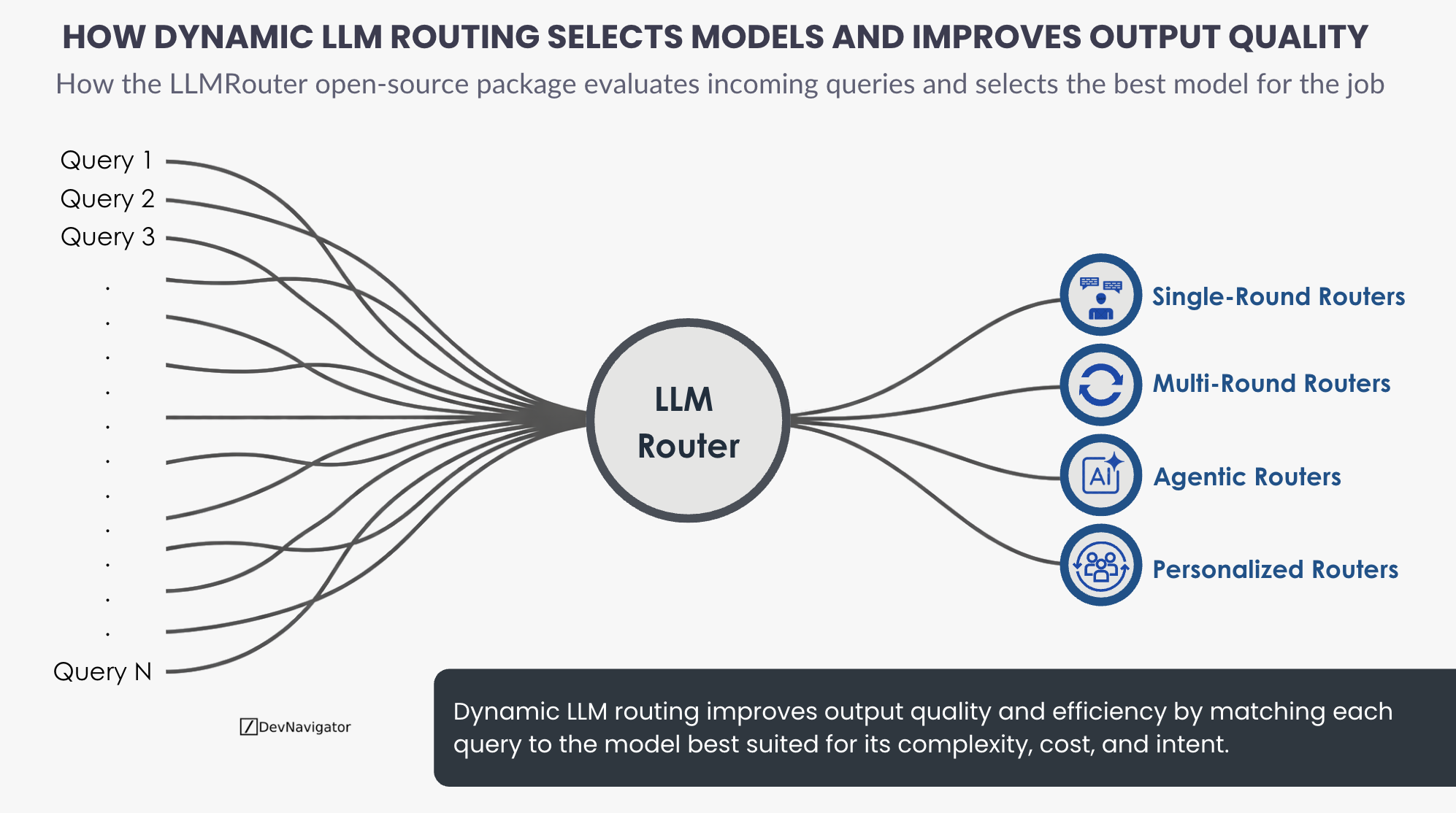
Dynamic LLM routing has emerged as a critical capability for teams deploying multiple language models at scale. Rather than relying…
-
Responsible AI Principles: 6 Essential Rules for Building Trustworthy AI
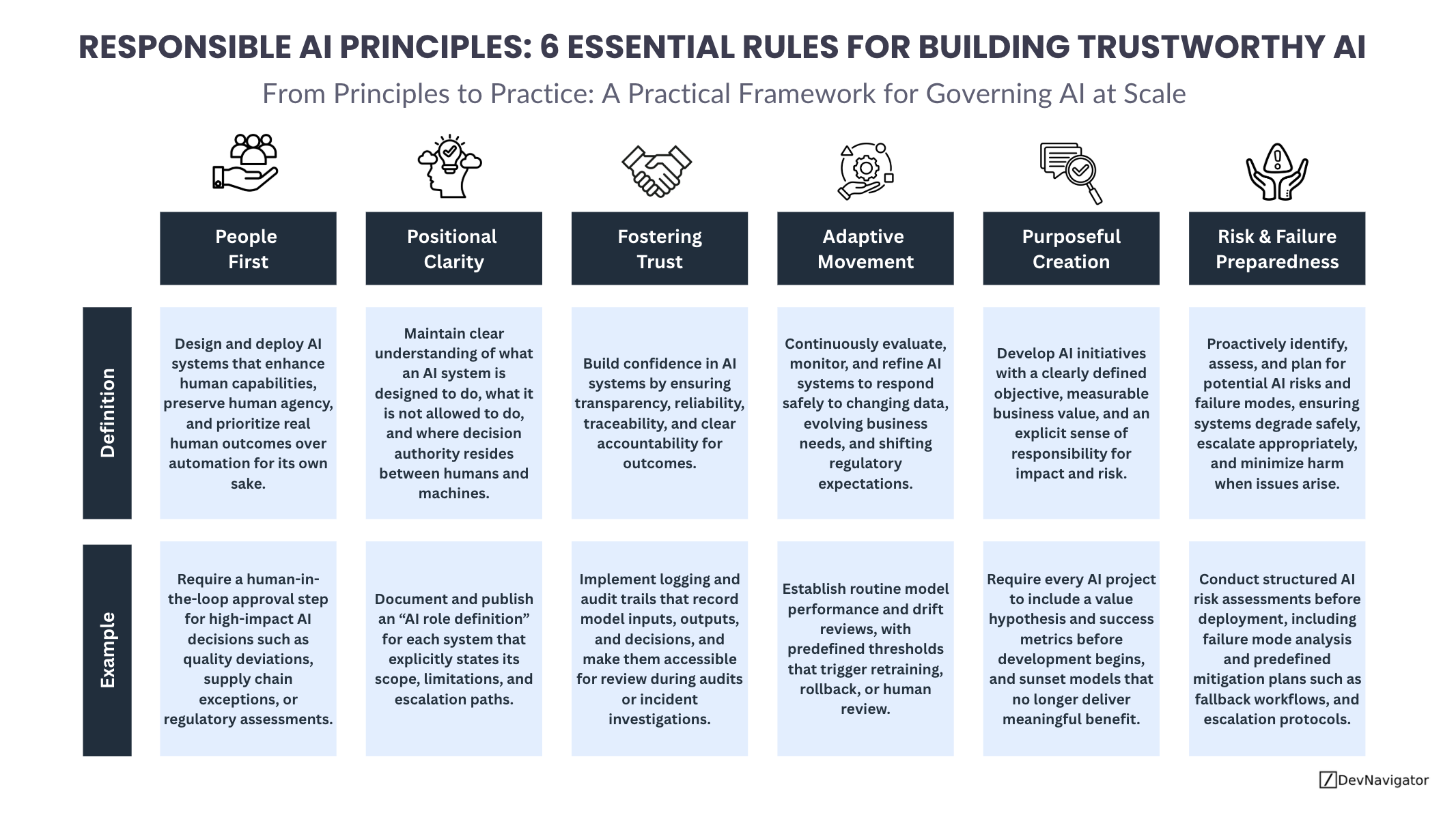
Responsible AI Principles are no longer abstract ideals reserved for policy documents or ethics boards. As artificial intelligence becomes embedded…
-
Enterprise AI Architecture: The 4 Critical Layers That Unlock Real Business Value
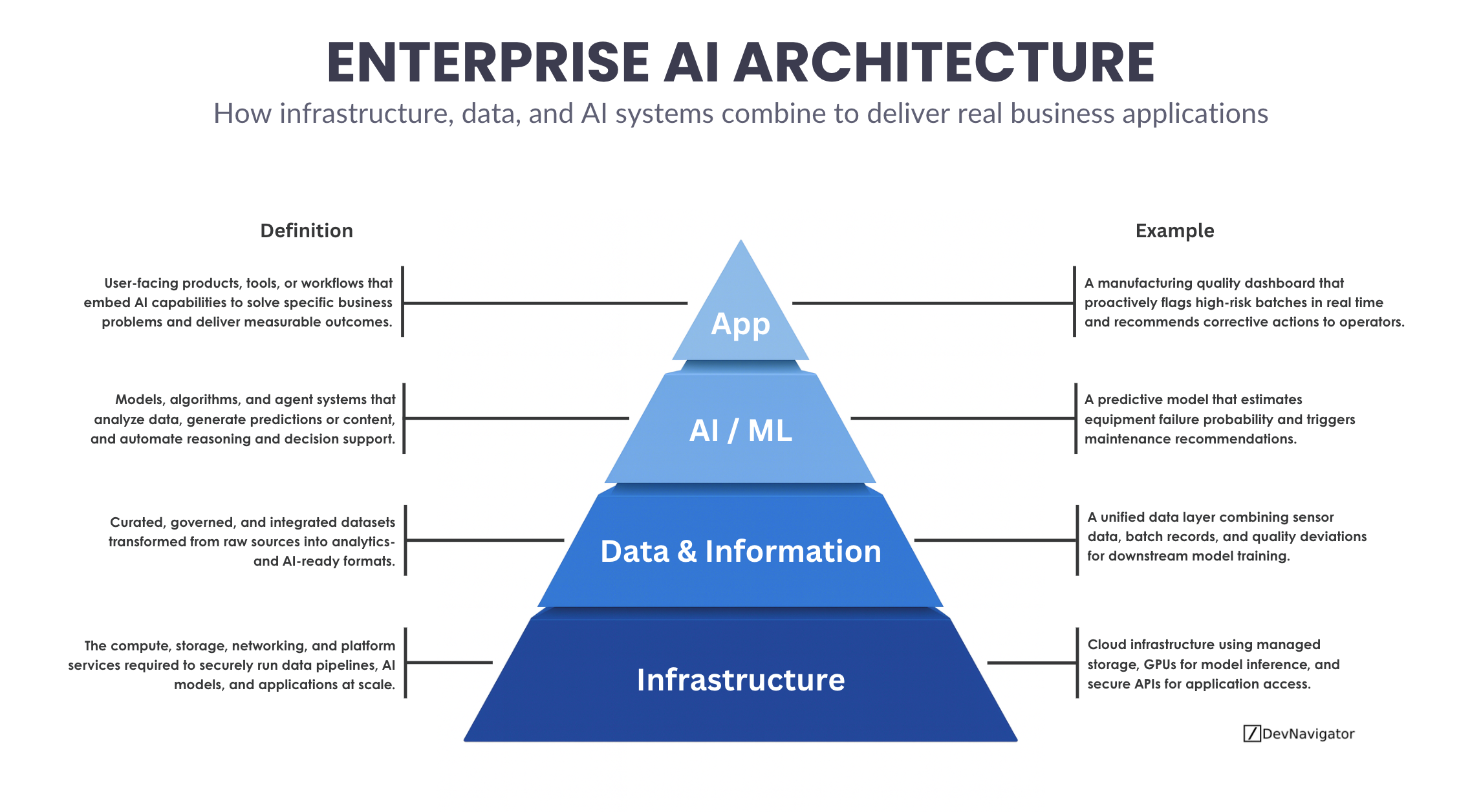
Enterprise AI Architecture is often discussed in fragments, infrastructure here, models there, dashboards somewhere else. In practice, successful AI systems…
-
How Large Language Models Actually Work: 8 Core Concepts Every Leader Should Know
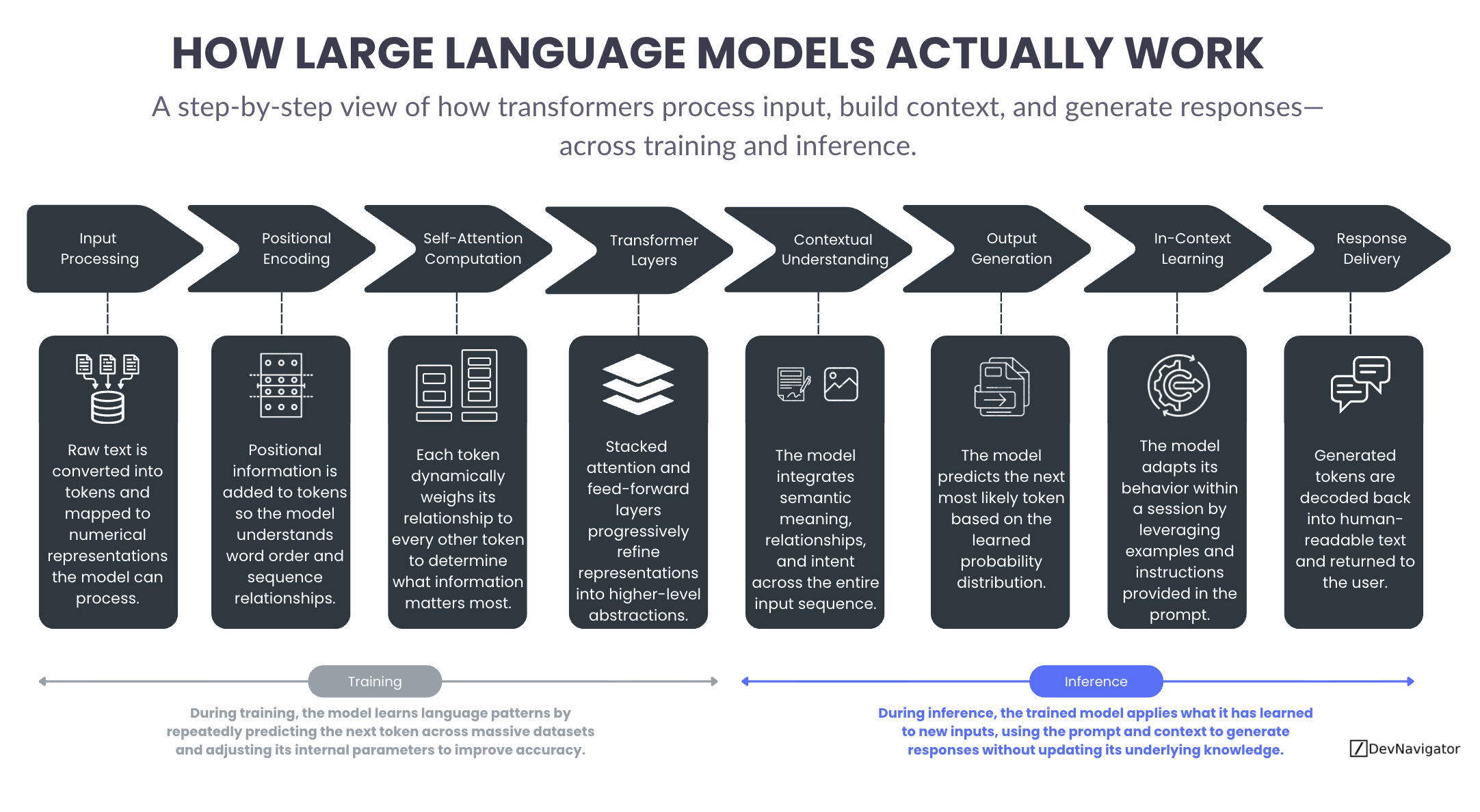
Large Language Models are often described as intelligent systems, yet the way they actually operate remains opaque to many leaders…
-
Enterprise-Wide AI Transformation: What McKinsey Found About High Performers

AI Transformation has moved past experimentation. For most organizations, the question is no longer whether to use AI, but whether…
-
Reinforcement Learning Made Powerful: 3 Architectural Insights from OpenTinker’s Cloud-Native Agentic Platform
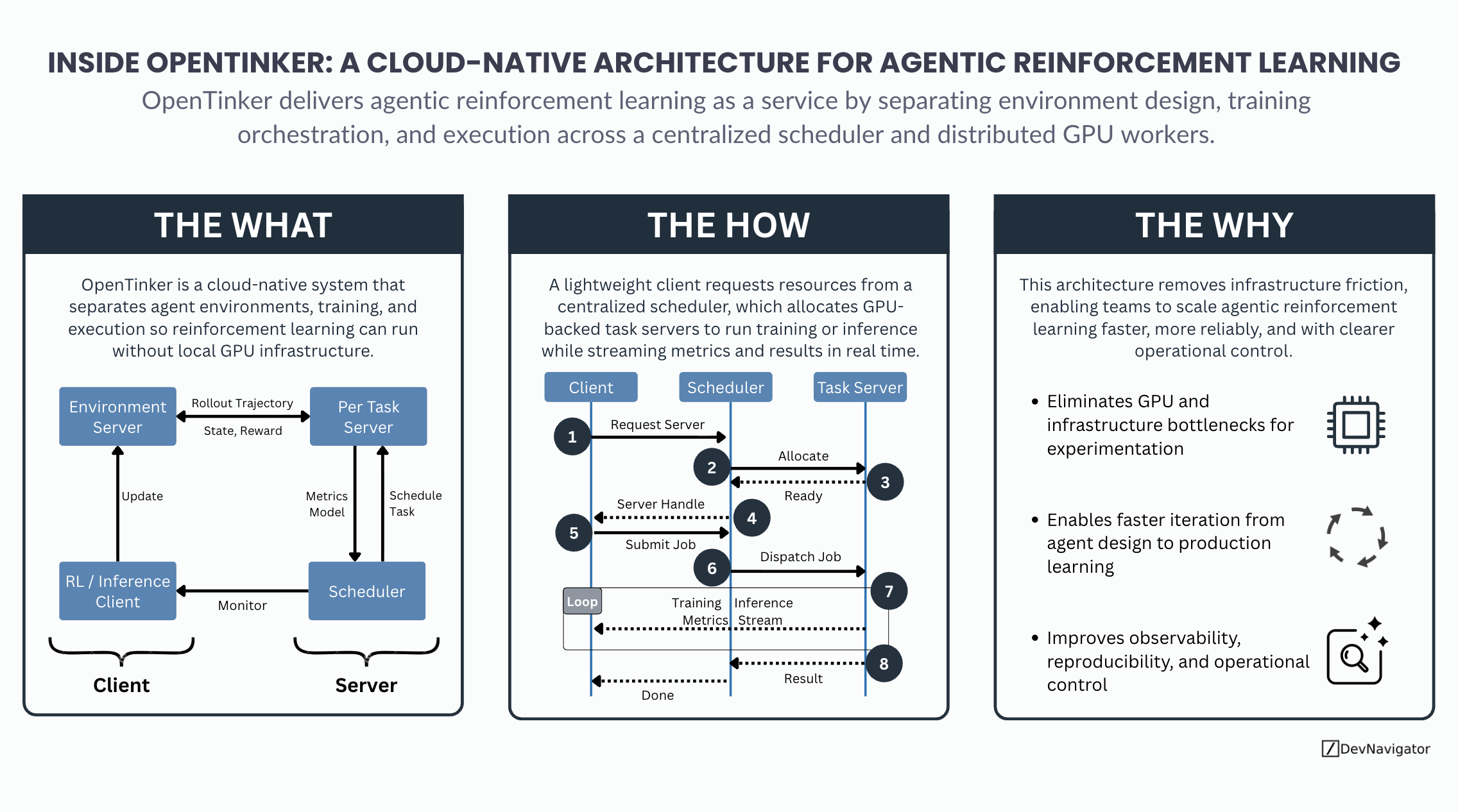
As reinforcement learning increasingly shifts from isolated research experiments to agentic systems embedded in real workflows, infrastructure has become the…
-
Prompt Caching Explained: A Smarter Method for Reusing Context to Cut LLM Costs
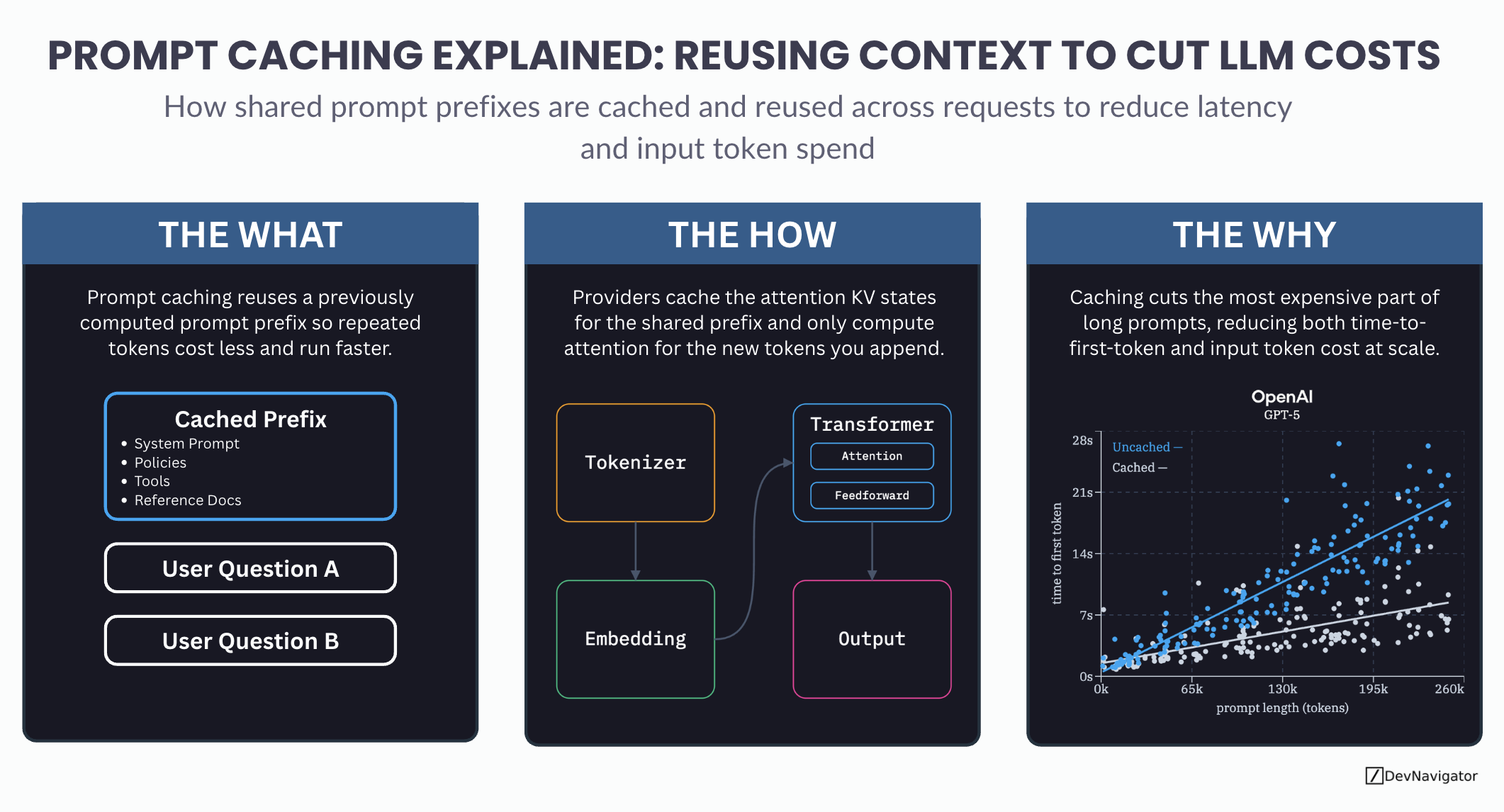
Prompt caching is one of the most important cost and performance optimizations quietly shaping modern LLM applications. As teams scale…

AI Strategy, Simplified Visually
Visual frameworks for AI strategy, emerging technology, and trending research, built for leaders and technical teams.
DevNavigator publishes infographic-first explanations of enterprise AI, agentic systems, governance, and data strategy, designed to help leaders and builders align faster, communicate better, and execute with clarity.
Browse by Pillar

AI/ML & Data Science
Models, LLMs, evaluation, RAG, agentic patterns, and practical ML concepts.

Strategy & Governance
AI operating models, transformation, governance, risk, and leadership alignment.

Business Applications
Use cases, workflow redesign, copilots, automation, and AI in real processes.

Business Performance & KPIs
Value measurement, metrics, ROI, productivity, and outcome-driven delivery.

Data & Infrastructure
Data foundations, platforms, pipelines, vector stores, and enterprise architecture.
Latest Infographics
About DevNavigator
DevNavigator helps leaders, managers, and builders make sense of AI strategy and enterprise technology through infographic-first storytelling. Use these visuals to align teams, explain complex systems, and drive real execution.
DevNavigator
AI Strategy, Simplified Visually.
© 2025 Recursiv LLC. All rights reserved.
Terms & Conditions | Privacy Policy | Contact Us | Donations
